3月下旬,Nvidia在加州总部为软件开发者举办了年度技术峰会GTC。会上,创始人黄仁勋发布了一款致力于大语言模型部署的GPU推理平台——H 100n l,在推理阶段将比最先进的A100快10倍。
但是这么先进的GPU是运不到国内的。去年8月,美国监管机构以国家安全为由禁止英伟达A100和H100 GPUs销售给国内企业,旨在减缓国内AI模型的传输速度,延缓中国人工智能的发展。
目前确实对国内AI企业影响很大。在巨大的计算能力需求下,呈现出“一卡难求”的局面,连阉割版A800都已经断货。
然而,与GPU硬件窘迫的局面不同,继3月16日百度发布文心怡雅大模型之后,国内众多科技、AI巨头相继公布了各大模型的发布日期:4月8日华为盘古大模型发布、4月10日商汤大模型发布、4月11日阿里大模型发布、4月14日同花顺举行AI产品发布会、国内大模型“百家争鸣”以及“GPU解禁后”。
这个4月成了国产大机型的混战期。
那么,在GPU有限的情况下,国内AI行业的发展情况如何,他们能交出自己的答卷吗?以后的发展会不会和国外越来越差?
本文平价学派以已经发布或即将发布大模型的企业及相关AI应用为例,通过专家访谈的方式,研究分析各类企业的AI大模型发展情况。
一个
华为盘古模型避开GPT
剑会横吗?
最近发布的华为盘古机型有些高开低走,没有太大的突破。尤其是C端几乎没有新的应用端产品,这主要体现了华为在B端智能化方向的技术实力,为华为的云服务和看得见的销售市场提供技术支持。
4月8日,华为云人工智能首席科学家田琦介绍了盘古大模型的开发与应用,包括NLP(自然语言处理)大模型、CV(机器视觉)大模型、科学计算大模型、多模态大模型、语音大模型的开发与应用。
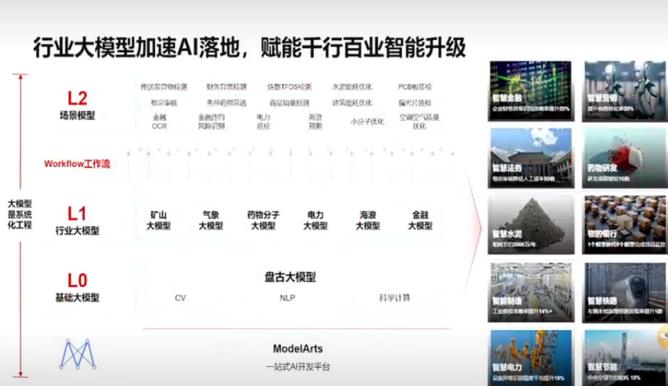
会前最有意思的是盘古的NLP模型。据介绍,该模型使用了深度学习和自然语言处理技术,并用大量中文语料库对其进行训练。
从参数和数据量来看,百度文心参数100亿,数据4TB。而GPT 4号达到1750亿,数据量45TB。华为盘古模型参数高达1000亿,数据高达40TB。盘古模型在参数方面接近GPT-3.5。
不过在这次发布会中,田琦并没有提到盘古NLP模型的相关应用。它只是以一种相对简单的方式介绍了过去已经发布的功能。相对而言,另外两个大模型着墨较多,用较多篇幅介绍了CV大模型和科学计算大模型的应用实例。这也让很多期待华为发布一款ChatGPT应用的“粉丝”有些失望。
但其实早在发布会前的相关交流中,内部专家就已经就此话题做出了相关回答:
“首先,在华为的发展历史上,很少出现新趋势后就立即追赶的情况。在公司30多年的发展中,基本上没有先发制人,一直采取的是后打打法,手机如此,云端如此,汽车也是如此,在这个领域也会如此。”
“如果你想做一个完美的NLP模型,这是一个团体级别的项目。通常情况下,决定会很慢,不太可能在一两年内出现。目前公司正在努力完成AI工程化和AI产品化。该公司认为,这是商业化必须走的路线。如果采用高度项目制,成本高,项目不可复制。所以华为的重心最终还是放在了面向行业的CV模式上。”
正如相关专家所说,最先进的盘古模型是CV(机器视觉)模型。
会上,田琦还表示,在过去的2022年,华为的盘古模式主要是面向工业的AI,为煤矿、水泥、电力、金融、农业等行业创造了更多的工业价值,其中CV模式早已在很多地方使用。
比如与能源公司合作的盘古矿模型,矿址是40米长的矿机,宽度只有2米左右。传统相机很难一次性捕捉到所有画面,只能使用画面中的九宫格视频画面。并且通过5G+AI全动视频拼接综采屏幕卷,传输到地面,未来地面工人可以实现地面控制机采,实现井下无人少人安全作业。
盘古煤矿模型还被用于监控煤矿主传送带的运行。煤矿收集后,通过一条主运输带从井下运输到地面。按照传统方法,工人配合操作。华为提议通过视频检查操作的安全规范。主要运输场景异物识别准确率98%,煤矿作业场景动作识别准确率95%,矿井安全事故减少90%以上。以上是CV大模型的落地应用。
此外,大模型还可以检测铁路机车的缺陷,如掉链、脱落、裂纹等潜在的不安全因素,人工检测成本较高。盘古大模型提供图像质量自动评估、故障定位、小样本识别等功能。

可以说,华为选择了一条不同于其他AI公司的道路——暂时放弃以ChatGPT为代表的C端需求,专注于B端产业需求的开发。
不可否认,华为作为中国被美国制裁最严厉的公司,无论从算力资源、公司发展理念还是商业化角度,选择一种专攻B端的打法都是对的。一方面可以避免庞大数据的训练,另一方面可以尽快为“寒冬”中的群体“造血”。
或许,在无法获得计算能力的时候,不在ChatGPT中纠结内耗,才是华为真正的AI之路。
2
拥有巨大的计算能力
商汤大模式,未来有隐忧
紧接着华为盘古模型发布,商汤科技的大模型即将登场。
但出于对上市公司的信任,公司目前处于发布大模型前的静默期,所以没有办法透露太多大模型的相关内容。但是,作为第一个把人工智能大模型写进招股书的公司,商汤确实有足够的实力推出自己的大模型。
在最近的交流中,商汤的人回答了一些关于计算能力的问题。
首先,大众最关心的是计算能力资源。商汤拥有极其丰富的GPU储备。对方说去年停售前有一万个A100芯片,完全可以覆盖训练一个有几千亿参数的语言模型的消耗。
除了NVIDIA的专用显卡,商汤还采购了国产GPU。专家表示,“比如寒武纪和广海,这两家公司可能是最近很多投资者非常关注的,想知道他们的产品是否已经进入大规模试用阶段。但是,如果你去年参观了我们在商汤的大装置,你应该会看到我们在大装置中适配了很多寒武纪和广海的GPU卡,我们也是寒武纪最大的客户之一。”。
在谈到国产替代时,专家也坦言,“我们很早就开始和国产GPU厂商合作适配国产GPU卡,但坦白说,目前大规模的模型训练只有A100和A800能胜任,国产GPU卡的易用性和性价比都没法比。不过在推理阶段,寒武纪最新的GPU在大规模模型领域也有不错的表现,预计未来会更好。
当被问及H100的出现是否会对国内AI企业造成冲击时,专家表示,H100加速芯片的出现确实显著提升了性价比。但如果不考虑性价比,现有的芯片完全可以胜任。
相比于众多AI企业,商汤在计算力技术的运用上优势明显。
在A100股票优先的情况下,如何利用仅有的资源做更多的事情,成为商汤要解决的一大问题。
专家表示,在过去的五年里,商汤科技拥有丰富的千卡并行培训经验。最大的单任务训练可以同时调动4000张A100 GPU卡,相当于10000张A100卡的计算能力,已经达到训练GPT3甚至GPT4的门槛。
商汤在国产GPU的优化适配方面也有丰富的经验。“目前10%左右的计算能力由国产GPU卡提供,商汤一直在适应。无论是寒武纪、广海还是现在的小规模提升,都有相应的适应支持。”
正是因为多年的训练经验,商汤获得了明显的优势。“我们目前的计算能力规模可以支持20个超大型的千亿级参数的模型一起计算,同时训练对于客户的技术迭代是非常明显的。救命啊。"
但当被问及目前面临的挑战时,专家们再次将焦点放在了国产GPU的适配上。也就是说目前的国产GPU还不能支持超大模型的训练,需要更多的投入来优化。另外,国产GPU虽然已经展现了一定的能力,但是还有很长的路要走。
总的来说,商汤科技作为第一批AI企业,有着极其深厚的培训经验,在禁运前获得了数万张A100显卡,这使得其在当下的AI大战中极具竞争力。
但是从另一个角度来看,禁运对高端GPU的影响短期内可以通过丰富的培训经验和更大的成本投入来掩盖,但是长期来看,如何持续获取高端GPU是商汤需要考虑的问题。如果禁运依然存在,国产GPU无法适应大模型的训练,那么国际前沿AI企业与最先进大模型的距离将继续被拉开。
三
阿里大模式上线
完全发达还是落后?

4月4日,哔哩哔哩首个全网视频ChatGPT的一个阿里版流出,引爆全网。当天下午,阿里官方宣布将在4月11日的阿里云峰会上推出大型机型。
从视频来看,阿里的大模式超出大家预期主要有两点:
一、“音色”、“文笔”、“意境”都可以改变,出现定制属性,受众大大增加。视频中,UP主先是用脱口秀演员“鸟鸟”的声音作为模特进行交流,然后以“猫妈妈”的身份要求ChatGPT跟进。整体定制特征清晰,不再局限于固定的形式,意味着每个人都可以根据自己的需求定制自己的“个性”。
第二,阿里GPT的成熟度超出预期,15个问题中有10个问题的答案明显优于国内公布的竞品,并且突破了复式对话,更加融合。
就在发布前一周,有内部专家接受采访,回答了“国产语言模型离ChatGPT还有多远?”。
专家表示,至少在未来一年到一年半的时间内,国货绝对不可能对标GPT4。只有赶上ChatGPT(GPT-3.5)才能谈GPT4。目前,国内大部分出版物仍然是文字、图像、视频等单一模式的形式,大规模的文字模式已经进入商业化阶段。百度已经迈出了第一步,其他很多AI公司和科技公司也将在年中或下半年发布。
在追赶GPT-3.5的过程中,还有三个核心瓶颈:
一是数据量不足。有了足够的数据才能继续训练,公开数据大家都可以买,所以最核心的竞争点就是如何获取足够的私有数据,权重比例大概在30%左右。
二是模式结构创新。目前国内语言模型做不到高层架构,所以做不到海量数据训练,这也是最大的瓶颈,权重达到40%左右。
第三是工程能力。项目落地的时候,大家都知道需要前期训练、优化训练、推理训练,但是实际部署的时候,完全是靠他们自己去摸索,包括数据处理、模型训练、模型优化、模型部署、应用,这些都需要大量的时间、精力和财力。这方面的权重和数据量差不多。
但这一切的前提是足够的计算能力。阿里目前拥有国内最多的A 100 GPUs,现阶段算力没有太大障碍,但随着禁运的持续和未来算力需求的增加,也会面临高端计算卡的短缺。
除了赶上ChatGPT,电商作为阿里起家的领域,也让人好奇阿里模式会给电商领域带来多大的改变。
专家表示,在电商场景下,推荐算法和生成营销模式和文本更重要。未来,阿里模式将涵盖营销模式、产品介绍和产品描述。
“实际上,去年,我们让一些商家使用了这项技术。我们选了几百个商家,估计请广告公司做营销模式要花几百万。阿里模型的AI可以胜任,覆盖40% 40%的工作量。”
“除了营销,还有虚拟直播等很多场景可以替代,包括仓储预测、物流信息挖掘等。要一步一步找场景渗透,慢慢替代老一代的技术,帮助中小企业,最终实现共赢。”
总的来说,阿里大模型作为一个庞大集团下的项目线,看起来并没有其他AI科技公司那么出彩。不过,目前阿里大文本模式的进度在国内也已经走在前列,其他模式也在有序推进。
但是,这一切的前提是足够的计算能力。随着技术的进步和数据量的增加,计算能力在未来可能仍然是一个不可逾越的坎。
四
股票价格猛涨
同花顺AI是翻新产品吗?
除了AI巨头和科技公司,各行各业的公司都已经将AI应用到实际业务中,同花顺就是其中之一。4月14日,同花顺还将举办AI产品发布会。
其实同花顺的AI产品用了很久,主要包括I-finance,基于AI技术的增值服务产品和B端AI产品。
其中,同花顺的主打产品是ai产品I蔡文。我问财经是目前财经领域比较成功的自然语言交互式问答系统。2022年,公司进一步加大RD投入,采用全新的语义解析方案,结合AI大模型、小样本学习等技术的应用,有效提升了我问财经信息服务的效率,将服务场景从金融领域拓展到通用领域,从中文场景拓展到多语言场景。
我们可以通过I-robot获得相关信息、数据和AI评论。还能准确提供a股公司的基本面和板块情况,并以各种图表的形式展现出来;还可以向金融机器人提问,实现条件选股,这是市场上比较成功的金融AI。
在AI之风的带动下,同花顺的股价也在上涨。从3月17日开始,短短12个交易日,股价从115.57元涨到最高239.22元,迅速翻倍。
股价飙升的背后,我们还不知道同花顺能否释放出更有价值的AI应用。但仅仅以目前的AI应用水平,是不可能支撑这么高的市值的。
而同花顺的AI含金量到底有多少,或许只有等它的产品发布了才能知道。
五
写在最后
看看国内已经公布的大规模文本模型或者AI应用,或者和各个企业的相关专家交流,可以发现一个问题,就是国内的大规模模型水平其实才刚刚起步。
硬件方面,英伟达高端GPU禁运,国内只有少数A100和阉割版A800可以用于训练和推理。目前可以通过丰富的训练经验和较高的资金投入,暂时掩盖国内计算能力严重不足的事实。但如果站得更高,GPU的发展就会严重落后,最终会成为杀死中国AI的利剑。
在算法层面,国内的AI公司也面临着极其尴尬的局面。让一群善于应用创新的公司直接做底层创新,无异于赶鸭子上架。国外的AI公司已经不开源了。
算法之后,如何找到模型开发的创新点是最难的。对于很多被卡在64楼的国产GPT车型来说,要对标ChatGPT甚至GPT-4简直是痴人说梦。
不可否认,应用层面的“软实力”可以让一个AI企业迅速找到盈利的目标,但真正的国内AI大战过后,硬件和算法层面的“硬技术”才是我们目前最缺乏的。
如果只关注应用层面,而忽略硬件和算法层面所创造的商业辉煌,那就好比井里的月亮,水中的花。虽然很美好,但一旦动荡就会转瞬即逝。只有具备计算能力和算法能力,才是中国AI发展的真正进步。
我们对计算能力和算法的争夺才刚刚开始。
此时此刻,中国的AI翻身仗还需要一些真正的“硬核武器”才能正式打响。
参考资料:
华为AI盘古模型研究框架,浙商证券